2 Getting Started
2.1 The tidyverse
We’ll be using the tidyverse ecosystem of R packages, which are really powerful data science tools that are perfect for these tasks.
We will mainly focus on learning how to use these two libraries:
dplyr: this is your best friend for transforming and manipulating data (data plyr)
ggplot2: incredibly robust and modular tool for building visualizations. Provides a lot of flexibility and a rich ecosystem of extensions.
We can install these if we haven’t previously installed them, we can install dplyr using install.packages():
install.packages('dplyr')And do the same for ggplot2:
install.packages('ggplot2')We only need to install libraries once on our computer, but any time we start a new R session we need to load the ones we want to use with library(). Let’s go ahead and do that to import the functionality of these functions for the rest of the scripts:
library(dplyr)
library(ggplot2)query_volume = query_volume %>%
mutate(date = as.Date(end_epoch)) %>%
group_by(subgraph_deployment_ipfs_hash, date) %>%
summarize(query_count = sum(query_count),
total_query_fees = sum(query_count*avg_query_fee))2.2 Prepare Data
We have pre-loaded some real query volume data from the QoS subgraph, which shows us query volume ~10 minutes behind real time, compared to on-chain query volume which can take 28 epochs, or never appear on-chain. The latest available data is from NA:
Note: you could download a .csv extract of the data above and follow along with every step past this point if you wanted to. This is not the expectation however, and you could only follow-along with this section because the rest of the sections interface with the indexer directly (also for data sources, not only applying operations).
The data provided is already very clean, but we can use the select() function from the dplyr library to select only the columns we care about, and in the order we want to see them in:
select(query_volume, date, subgraph_deployment_ipfs_hash, total_query_fees, query_count)## # A tibble: 0 × 4
## # Groups: subgraph_deployment_ipfs_hash [0]
## # ℹ 4 variables: date <date>, subgraph_deployment_ipfs_hash <chr>,
## # total_query_fees <dbl>, query_count <dbl>Notice how in the results above the first column is date, and we only kept 4 columns instead of all 8.
Let’s overwrite the existing query_volume dataset by specifying as = to the previous result:
query_volume = select(query_volume, date, subgraph_deployment_ipfs_hash, total_query_fees, query_count)2.2.1 Filter Data
Nice! Next up, let’s work towards visualizing the query volume of a particular subgraph 📈. The first thing we want to do is filter our data to one specific subgraph deployment, and save the results in a new dataset we can use for the visualization. This time we can use the filter() function, which is still from dplyr, to only return rows that match a specific condition.
On the original data query_volume, we can apply the filter() function, and only match rows where the subgraph_deployment_ipfs_hash is QmUzRg2HHMpbgf6Q4VHKNDbtBEJnyp5JWCh2gUX9AV6jXv:
# start with the data
query_volume %>%
# filter to rows matching a specific subgraph_deployment_ipfs_hash
filter(subgraph_deployment_ipfs_hash == 'QmUzRg2HHMpbgf6Q4VHKNDbtBEJnyp5JWCh2gUX9AV6jXv') %>%
# show most recent rows first
arrange(desc(date))## # A tibble: 0 × 4
## # Groups: subgraph_deployment_ipfs_hash [0]
## # ℹ 4 variables: date <date>, subgraph_deployment_ipfs_hash <chr>,
## # total_query_fees <dbl>, query_count <dbl>In the command above, we checked for subgraph_deployment_ipfs_hash matching the value using ==. This produced a value of True/False for each row, and only gave back rows where the match was True. We use == because = is reserved for assigning things.
Here we use a “pipe operator” (%>%), which lets us start with our dataset, and clearly apply one operation at a time like the code above. That is all you need to conceptually understand, but make sure you understand what action we are taking in the example above. You can read more about the pipe operator in this concise bonus section example at the bottom of this page.
Let’s run the same exact code as the above, but add subgraph_data = to the start, to save the new results to a new dataset we are creating subgraph_data:
# start with query_volume, filter to subgraph, assign results to new data "query_volume"
subgraph_data = query_volume %>%
# filter to rows matching a specific subgraph_deployment_ipfs_hash
filter(subgraph_deployment_ipfs_hash == 'QmUzRg2HHMpbgf6Q4VHKNDbtBEJnyp5JWCh2gUX9AV6jXv')Now we can view the new data which was filtered to the specific subgraph:
subgraph_data## # A tibble: 0 × 4
## # Groups: subgraph_deployment_ipfs_hash [0]
## # ℹ 4 variables: date <date>, subgraph_deployment_ipfs_hash <chr>,
## # total_query_fees <dbl>, query_count <dbl>R only does exactly what you ask it to do. So when we just execute subgraph_data, this simply returns the unchanged/current dataset or R object. If we apply filter or other operations and don’t assign the result to a new variable with =, we will see the results of the data with the transformations applied. If we then stored those results in a new dataset, it would no longer print the results until we asked it for the new data.
From this point forward we won’t keep showing the code that just prints the new data as it doesn’t add new material information and makes the tutorial more concise.
2.2.2 Mutate/Transform
This is looking pretty good! The only thing we still need to fix is the date which has a character data type, and we want to convert to a Date type to make our life easier in later steps. To do this, we can use the mutate() function to apply a transformation on the date column of the data. We will simply use as.Date() to convert the column, and overwrite the same column:
subgraph_data %<>%
# convert to date
mutate(date = as.Date(date))## # A tibble: 0 × 4
## # Groups: subgraph_deployment_ipfs_hash [0]
## # ℹ 4 variables: date <date>, subgraph_deployment_ipfs_hash <chr>,
## # total_query_fees <dbl>, query_count <dbl>2.3 Visualize Results
Next we will start using functions from ggplot2 to start visualizing data. We already imported this library earlier, so we can go ahead and start using ggplot() and related functions.
Our starting point is always our data, so we start with: subgraph_data %>%
Then, we want to map the chart to the correct x and y variables. We can use aes() which stands for aesthetics, and map the x variable to date, and y to query_count, which will give us a visualization of query count over time:
subgraph_data %>%
# set ggplot mappings
ggplot(aes(x=date, y=query_count))
But wait - what about the actual visualization?
We only established what should be on the x and y axis, but we didn’t specify what we actually want to visualize. Let’s go ahead and add a point for each observation by adding another layer to the chart with geom_point():
subgraph_data %>%
# set ggplot mappings
ggplot(aes(x=date, y=query_count)) +
# add actual points to the chart
geom_point()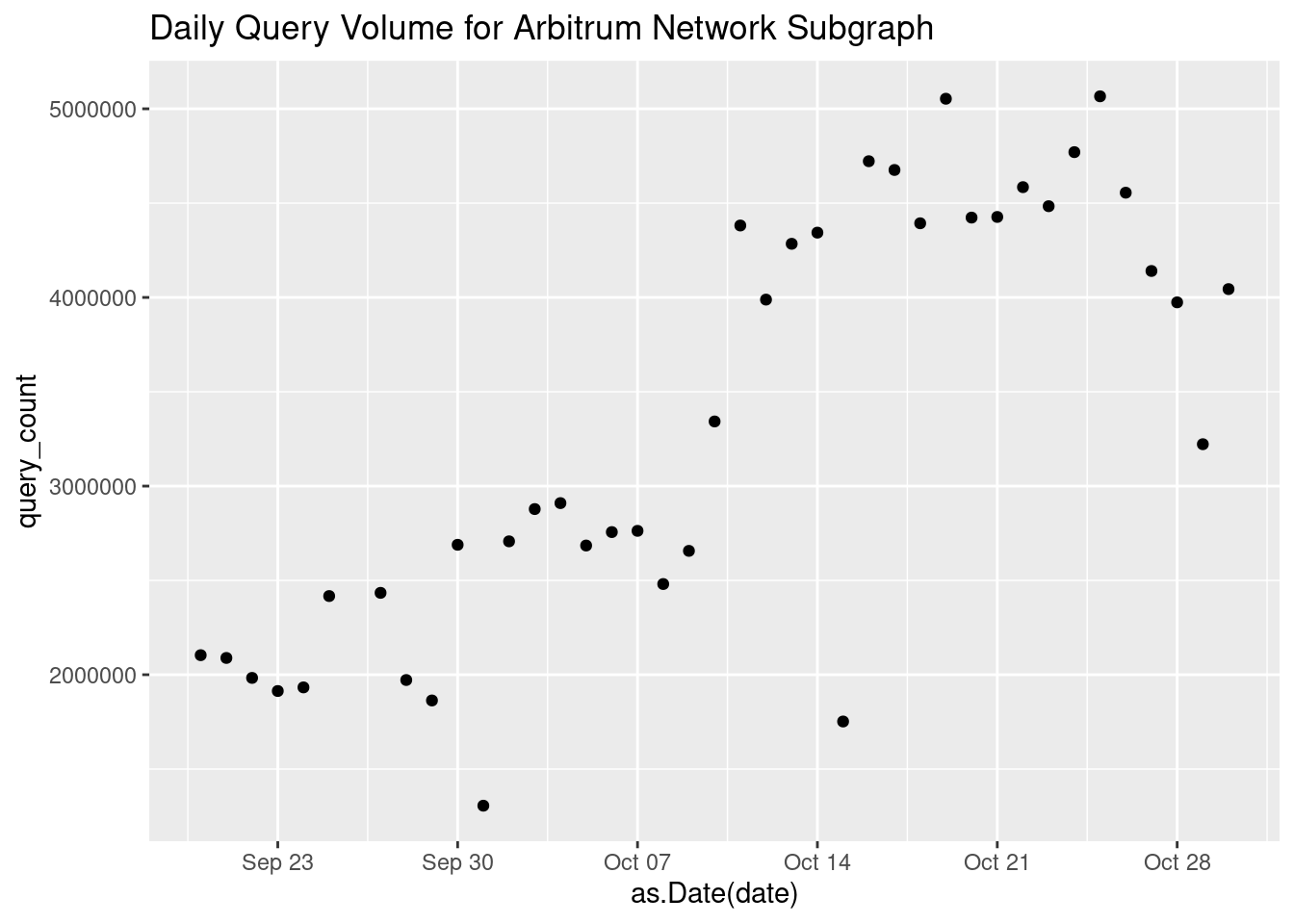
In more complex examples we can map additional layers to different things, but in this case by just adding geom_point() ggplot already understands what we want because we told it which variables we want on x and y axis, and what we want to visualize those observations as.
Within the ggplot usage, we use + which is conceptually the same as %>% to make changes to the plot. We use %>% when we start with an R object, but use + to add new layers to a chart in ggplot.
We can save the current chart in subgraph_chart, and keep adding new changes from this point:
subgraph_chart = subgraph_data %>%
# set ggplot mappings
ggplot(aes(x=as.Date(date), y=query_count)) +
# create a line
geom_point()Now we can make changes to subgraph_chart, for example we can add a title with ggtitle()
subgraph_chart + ggtitle('Daily Query Volume for Arbitrum Network Subgraph')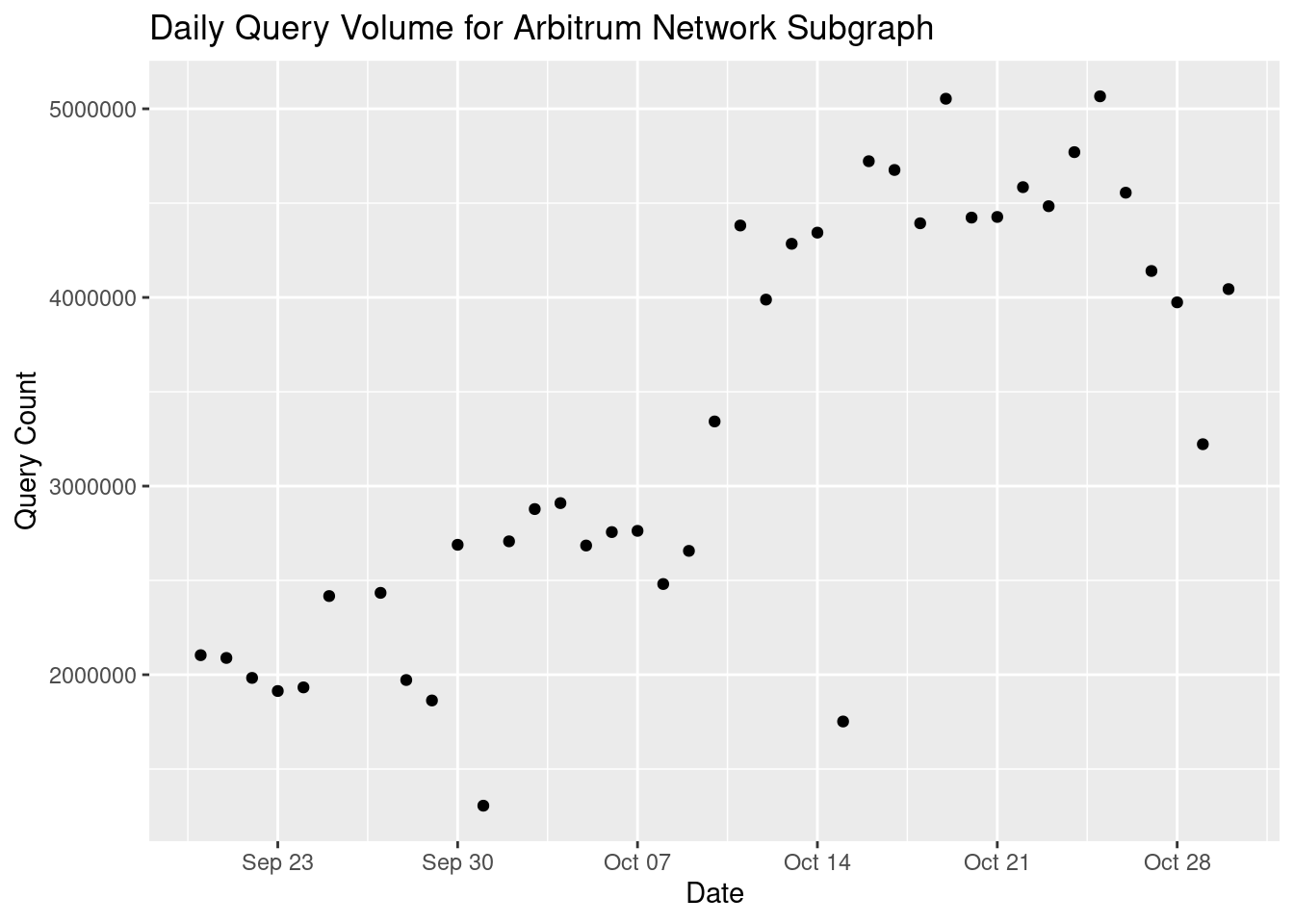
Let’s add the title like above with ggtitle, and also add xlab() and ylab() to change the x and y axis labels.
subgraph_chart = subgraph_chart +
# add title
ggtitle('Daily Query Volume for Arbitrum Network Subgraph') +
# change x-axis label
xlab('Date') +
# change y-axis label
ylab('Query Count')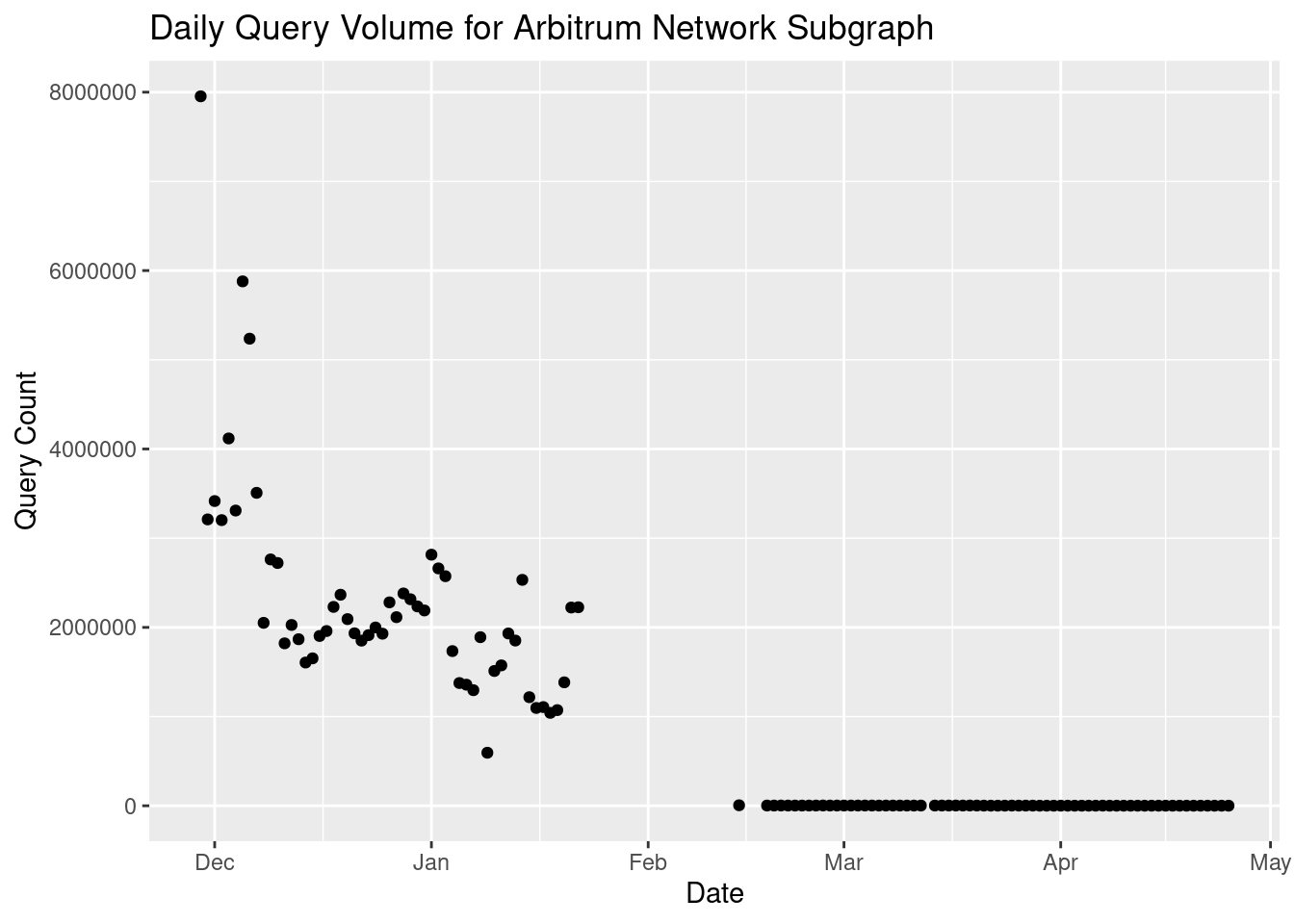
Let’s make the numbers on the y-axis more readable by adding commas. We will use scale_y_continuous() and specify the labels as comma. comma is an extension outside of the base ggplot2 library, so we first do library(scales) to import what we need:
library(scales)
subgraph_chart = subgraph_chart + scale_y_continuous(labels = comma)
# View modified chart
subgraph_chart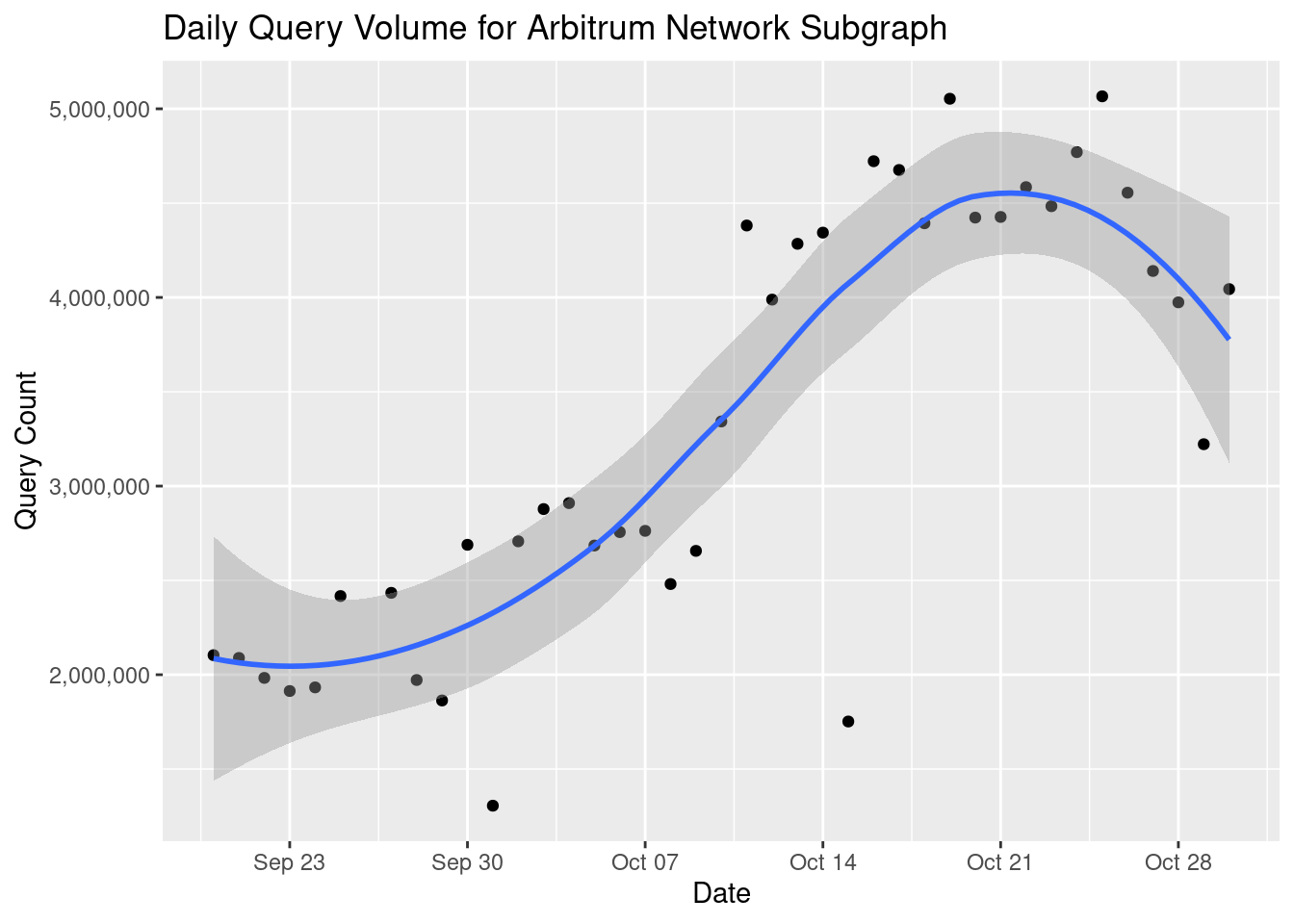
Nice! From this point there are a number of cool things we can do. Let’s start by taking the chart we have, and making it interactive. To do this, let’s import the plotly library, and simply wrap our chart in ggplotly():
library(plotly)
# wrap chart in command that makes it interactive
ggplotly(subgraph_chart)The above maintained our chart, but you can now hover over the data points and view their precise values.
We can do a bunch of other things. We can add a line showing the trend over time adding stat_smooth() to the chart:
subgraph_chart + stat_smooth()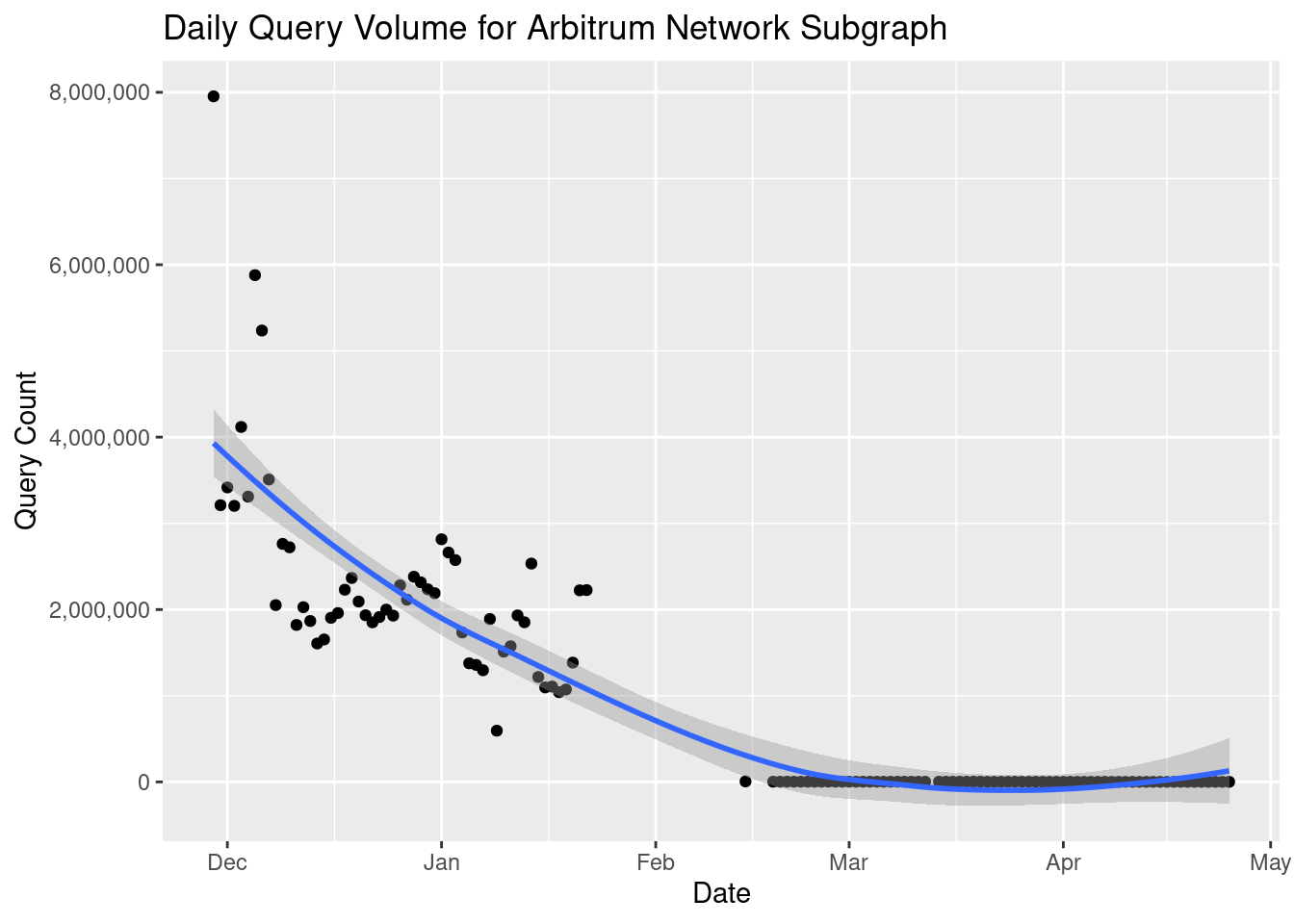
Or a linear regression line:
# Add linear regression line
subgraph_chart + stat_smooth(method = 'lm', color='red')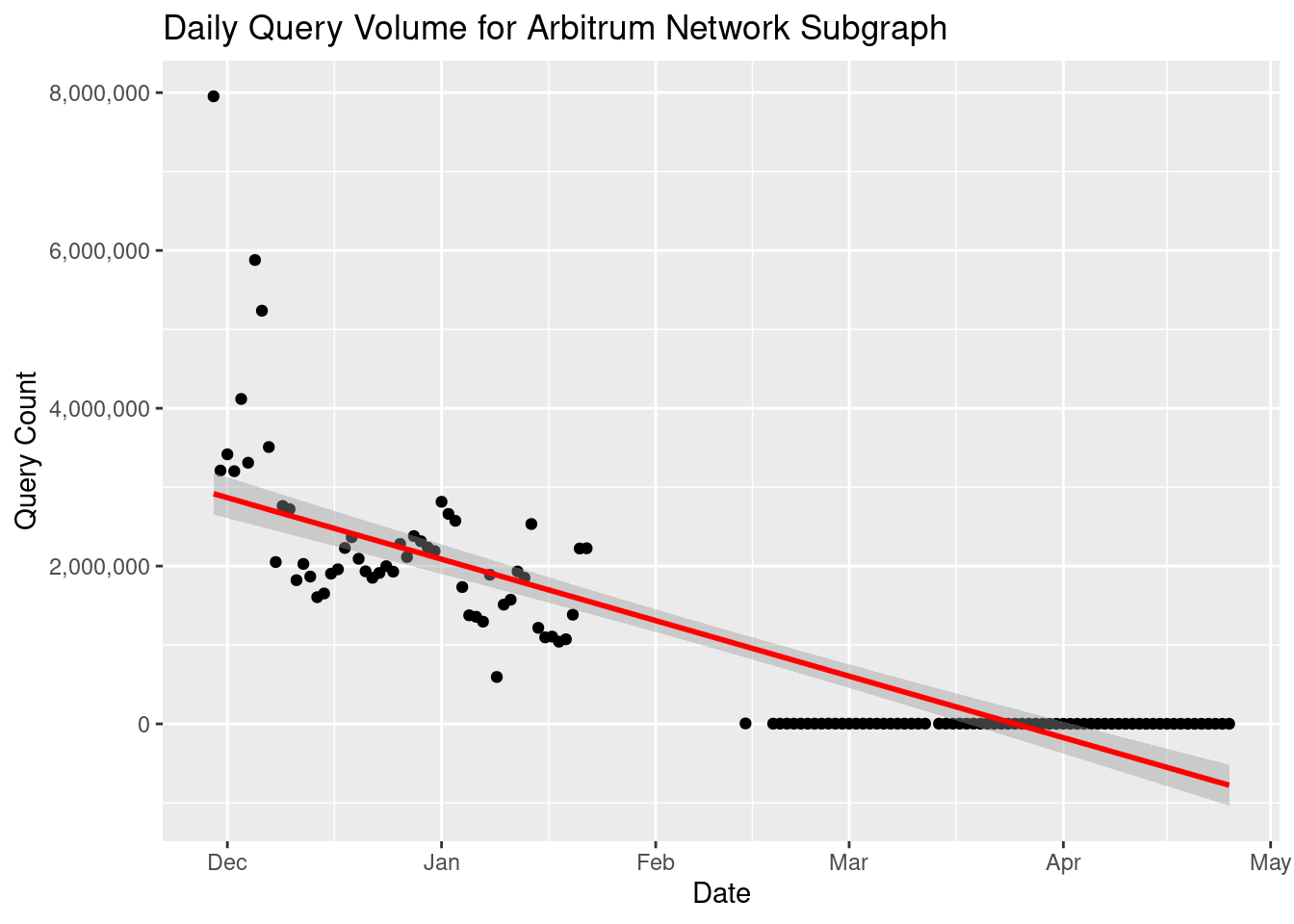
We will get more sophisticated with this in a second when we produce a forecast. For now, let’s keep improving the look of the chart.
Let’s bring in the ggthemes extension, and apply a theme using theme_economist():
library(ggthemes)
# apply theme
subgraph_chart = subgraph_chart + theme_economist()
# view chart with theme applied
subgraph_chart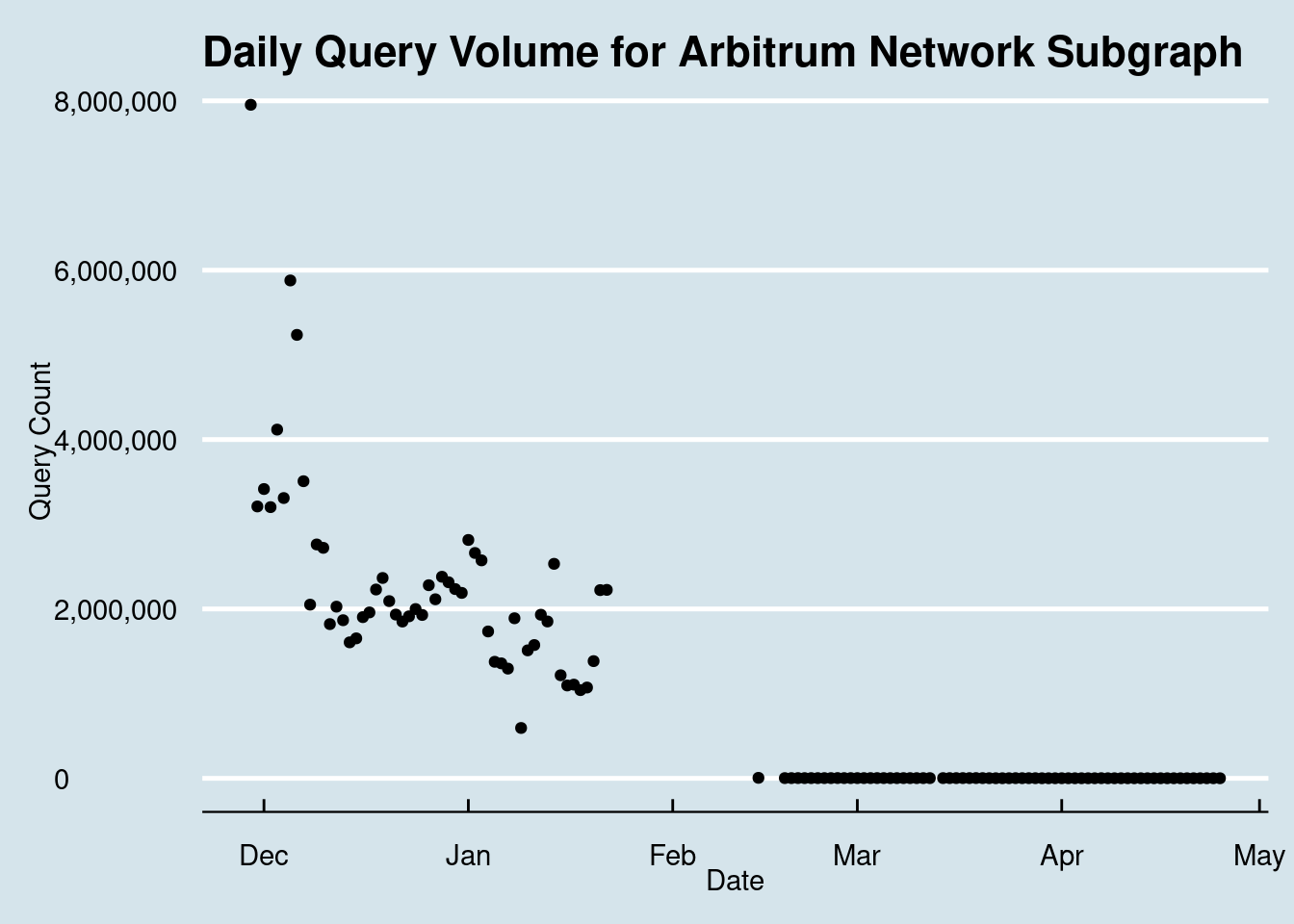
–>
Nice job! Now you have everything that you need to conceptually follow-along with each step. Let’s jump right in and start by closing our active allocations
save.image('/root/github/indexer_analytics_tutorial/data/chapters_snapshots/02-getting_started.RData')